
Data Spaces Blueprint Building Blocks (shared)
Early draft
Please be aware that the Data Spaces Blueprint content shared in these pages are a very early draft published on 2023-07-01. The current draft is incomplete and the content might still change.
SAVE-THE-DATE 01-10/09/2023: We will welcome your feedbacks to future improve the Data Spaces Blueprint during the Public consultation that will open on September the 1st 2023 until September the 10th. Please mark these dates in your calendar and get ready!
The Data Spaces Blueprint is a consistent, coherent and comprehensive set of guidelines to support the implementation, deployment and maintenance of data spaces. The blueprint contains the conceptual model of data space, data space building blocks, and recommended selection of standards, specifications and reference implementations identified in the data spaces technology landscape.
The figure below illustrates the assets, developed by the Data Spaces Support Centre. These assets are part of the Data Spaces Blueprint and range from introductory information to in-depth knowledge about standards and reference implementations. Below the figure, each of the assets within the data space blueprint are described in more detail.
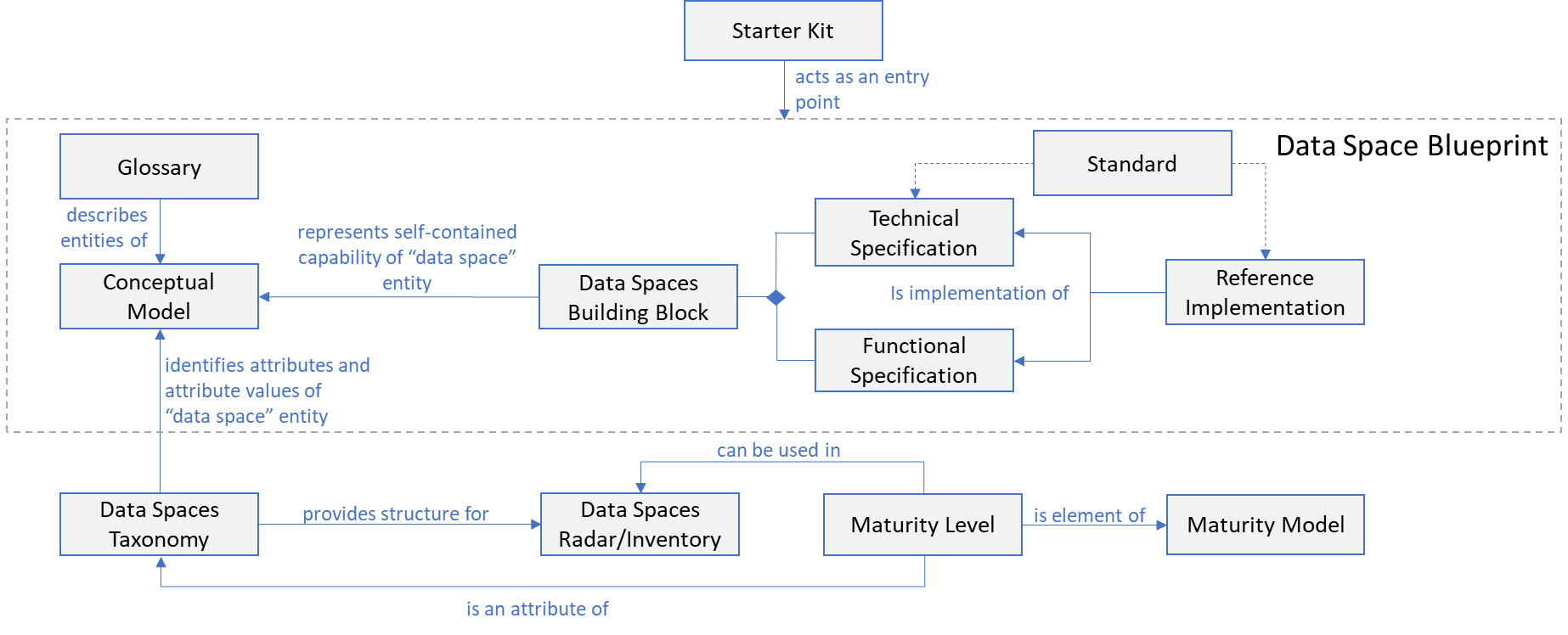
The following items are available which are not specific to a single building block but rather to the overall Data Spaces Blueprint.
Glossary: is a curated set of terms (“names” of the entities) and definitions (“criteria” enabling to check if something qualifies as an instance of the term). The current version of the glossary can be found at Data Spaces Glossary.
Conceptual Model: a model of the data space domain which represents the concepts (entities) and the relationships between them.
For each building block, the following information is provided:
Functional Description of each building block: the functional description describes the key concepts of the building block and their interrelationships with other building blocks, without going into too much detail or technical specifics. The functional descriptions of all building blocks can be found at the individual building block pages.
Technical Specification of each building block: detailed description (e.g. requirements) of the functions and capabilities that the building block should fulfill. It outlines what the building block is supposed to entail, and which choices can or should be made as part of implementing this building block. Compared to the functional descriptions, detailed specifications describe specific functions using jargon, more formal technical language or models such as workflow descriptions and behavior of the building block.
Moreover, this layer contains technical specifications, which entail technical details and guidance as how standards and (reference) implementations should be used, especially if multiple standard or (reference) implementations need to be used together. The functional description and detailed specification are both used for compliancy of standards and (reference) implementations and to ensure interoperability within and across data spaces.Standards: a description of best practices or technologies which are most appropriate standardized solutions. Standards can be formal standards or informal standards. The data spaces blueprint focuses on open standards.
Reference implementations & Best practices: a realization of a building block, which can be an (open-source) software component, best practices of a governance & legal building block. A (reference) implementation is an implementation of a standard that can be considered a reference for all other implementations that realise the same specification or complies with the same standards Moreover, this layer contains example usages, demonstrations, and practical guidelines for using this implementation/best practice.
Building Block descriptions
This section contains a description of all the building blocks which are part of the Data Spaces Blueprint. In total, the DSSC identified 16 building blocks. As the figure below indicates, the categories the building blocks into two main categories: organisational & business, and technical building blocks. Next, each of the two main categories are divided in three sub-categories.
The sections below briefly introduce all categories and building blocks. More information can be found by clicking on the headings of a sub-category or building block.
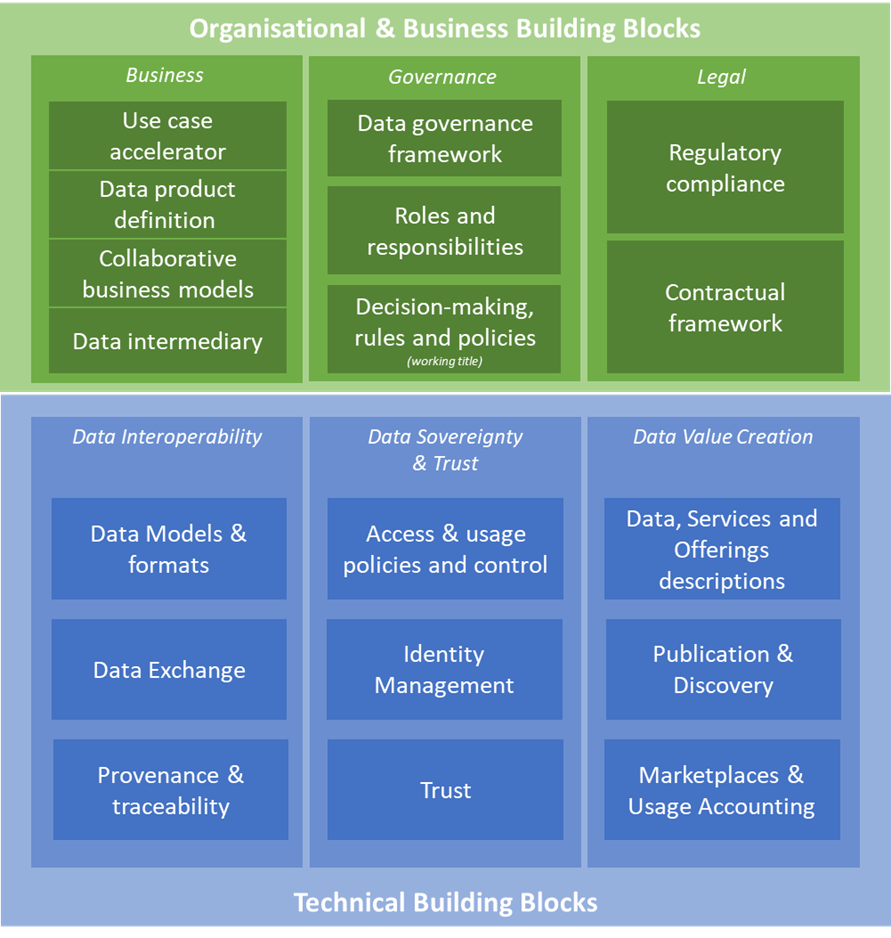
The Building Block Taxonomy
Organisational & business building blocks
Data spaces are being set up to achieve societal or business objectives. Costs for setting-up and managing data spaces need to be covered. In addition, some companies providing value-added services are seeking a for-profit business model and business case. This all needs to be balanced and needs to operate within a legal framework consisting of legal agreements and adhering to legislation. The first category of building blocks contains those necessary for business and organizational purposes.
Business models for data spaces
Data spaces can be seen as a strong and collaborative approach to platforms, also called multi-sided business models. A business model of a data space shows how value is created, delivered, and captured. An important driver of the value of multi-sided business models is the establishment of network effects between “supply” and “demand” of data. Offering a useful collection of data sources will attract data users, and a large user base will attract offerings of additional data sources.
This building block category consist of 4 building blocks
Legal frameworks for data space
A number of legal issues affect the creation and operation of data spaces and need to be addressed by the governance model. For example, it is important to ensure compliance with relevant horizontal legislation, such as data protection, competition and intellectual property laws. In addition, the complex mix of national and EU legal entitlements to data, the ambitious European legislative agenda, and the intricate interplay between different relevant regulatory instruments make navigating the legal aspects of data governance a challenging task.
As data spaces often involve multiple parties with different interests, contracts also play an important role in the governance of data spaces by setting out the terms and conditions for data sharing and cooperation between different participants. These contracts can mitigate potential disputes and ensure more efficient and effective management of the data space.
This building block category consists of
Currently, the descriptions of the building blocks are still pending. The building blocks will be updated in the next revision of the Data Spaces Blueprint.
Governance of data spaces
Governance can be understood as the creation, development, maintenance and enforcement of a governance framework for a particular scope. Within a Data Space, governance is needed to configure and coordinate the necessary actions of the different organisations involved in the Data Space to achieve their goals and progress through the different lifecycle stages of the Data Space. Governance in a Data Space is multi-faceted, encompassing business and legal aspects as well as technical and operational elements.
Governance has been underexplored in previous literature on Data Spaces, and the DSSC therefore focuses on expanding this part to support the development of Data Spaces. Clear and trustworthy governance frameworks are vital for the Data Spaces.
The building block category consists of
Data governance framework
Roles and responsibilities
Decision-making rules and policies
Currently, the descriptions of the building blocks are still pending. The building blocks will be updated in the next revision of the Data Spaces Blueprint.
Technical building blocks
The following sections describe the 9 technical building blocks, divided into three categories: data interoperability, data sovereignty & trust, and data value creation.
Data interoperability building blocks
Data spaces should provide a solid framework for an efficient exchange of data among participants. An individual or organisation is never just part of one single space but operates in different data spaces simultaneously. If different approaches are adopted for interoperability, we will end up with silos providing a barrier for data sharing.
Therefore, it requires the adoption of a “common lingua” every participant uses, materialized in the adoption of interoperable APIs for the data exchange, and the definition of compatible data models. Compatible mechanisms for traceability of data exchange transactions and data provenance, are also required.
Data models and formats
Semantic interoperability is of great importance for a data space. A data space requires participants to be able to understand each other in order to provide value to the data. This requires a common language for the level of semantic interoperability that is required to be able to automatically understand and exchange digital resources. To semantically annotate the data that is being shared, a data space initiative requires a domain specific vocabulary (e.g., an ontology with a shared conceptualization of a particular domain of knowledge). However, how do you get data space participant to use a common language? The development of such vocabularies is often organized centrally by business communities and delegated to some sort of standards development organisation (SDO) that publishes and maintains shared domain vocabularies and data schemata.
Data exchange
The Data Exchange provide the means for the exchange of data between two or more participants of a data space. It defines the format/ syntax of data exchanged between systems of each participant, as well as the methods and procedures to transmit and receive the data.
Recall that the building block on Data Models & Formats describes the modelling of the knowledge and information within the considered domain. The Data Exchange building block, on the other hand, provide the means how interaction between systems, and/or data members, and between systems themselves is achieved. Unlike a domain specific vocabulary, it is more concerned with the “how” data is exchanged rather than the “what” data is exchanged.
Exchanging data between different applications in a data space comes with many different data formats, protocols and APIs. It is therefore desirable that data space initiatives adhere to a widely accepted protocol that enables communication between different devices or applications. By standardizing the communication protocols a data space initiative can ensure interoperability as the data is transmitted accurately across data space participant.
Provenance & Traceability
Especially data spaces with highly regulated data, it is necessary to make the data sharing process observable. This can be done for legal reasons to prove that data has been processed only by authorized entities, or for business reasons to provide a marketplace and billing function through a trusted third party. Observable data is important for ensuring that data is being used in a way that is consistent with the contractual arrangements and governance frameworks
By making the data sharing process observable, it is possible to monitor data usage and ensure that the data is only being accessed by the authorized parties. Provenance and traceability relates to the administrative part of the transaction.
Data sovereignty & Trust building blocks
Data spaces should bring technical means for guaranteeing that participants in a data space can trust each other and exercise sovereignty over the data they share. This requires the adoption of common standards for managing the identity of participants, the verification of their truthfulness and the enforcement of policies agreed upon data access and usage control.
Access & usage policies and control
This building block refers to the ability of organisations to define and implement policies regarding who can access data services and the processing of data. By defining and enforcing access and usage policies, organisations in a data space can better protect their data and ensure that it is being used appropriately.
An organization should have the capability to both specify and enforce usage policies. It adds an additional layer of security and control to the authorization and authentication processes.
Access and Usage Policy Enforcement - Functional Specifications
Access and Usage Policy Enforcement - Technical Specifications
Identity Management
Identity management is a critical aspect of data space security and governance. To ensure that the data remains secure and confidential, it is essential to implement identity management processes. This includes identification, authentication, and authorisation of stakeholders operating in a data space.
Identity management ensures that organisations, individuals, machines, and other actors are provided with acknowledged identities, and that those identities can be authenticated and verified, including additional information provisioning, to be used by authorisation mechanisms to enable access and usage control.
To ensure data sovereignty in a data space, it is essential to prove the identity of any entity within it. It is also necessary when you want to grant someone access to act on your behalf. Fortunately, there are many solutions available for authenticating and authorizing proof of identity. For instance, eIDAS 2.0 can be used to identify a natural entity, and decentralized identifiers can be used to authenticate through the use of verifiable credentials. Their application in the context of data spaces is being explored as part of this building block.
Trust
In general any entity within a data space can make claims about other entities and issue self-signed proofs. However, without a structured system of underlying trust chains, these proofs would be of no use. Therefore, within a dataspace a trust anchor is needed to validate matters such as identity or self-descriptions. But also to validate whether an entity belongs to a specific data space.
Such functionality is important for other participants in the data space to be able to work with an initially unknown or untrusted entity. Trust anchors can be needed for the validation of identities, and/or self-descriptions of data & services.
Data value creation building blocks
The primary function of a data space is to enable participants to discover and access data shared by others in order to generate value. Data spaces can provide support for the creation of multi-sided markets where participants can generate value out of sharing data (i.e., creating data value chains).
This requires the adoption of common means for the description of terms and conditions (possibly including pricing) linked to data services and data service offerings, the publication and discovery of such offerings and the accountability of all the steps during the lifecycle of contracts established when a given participant acquires the rights to access and use a given data service.
Data, services and offerings descriptions
Self-descriptions are a crucial component of a data space: it provides a meta-model of data, services and offerings in a data space. This should allow participants in a data space to find and select suitable services.
A metadata model should be linked to elements in other building blocks such as identities and semantics in specific domains. Self-descriptions can also link usage policies, provenance details, technical descriptions (e.g, the data schema, API specifications) and the content related descriptions. It should be possible to include self-descriptions in a catalogue.
Data, Services and Offerings Descriptions - Functional description
Data, Services and Offerings Descriptions - Technical Description
Publication & discovery services
Once individual self-descriptions have been created, it should be possible to publish them in a catalogue and enable other participants of the data space to find them. This is the scope of the building block for Publication & Discovery.
Marketplaces & Usage Accounting
Data spaces can provide support the creation of multi-sided markets where participants generate (monetary) value out of sharing data. This building block describes common mechanisms for establishing marketplaces of data and the related usage accounting (e.g. for billing).
Data Space Connector/Protocols
The Data Space Protocol is used in the context of data spaces with the purpose to support interoperability. It features a a set of specifications designed to facilitate interoperable interactions (e.g., data sharing) between entities governed by usage control and based on web technologies. These specifications define the schemas and protocols required for entities to, e.g., publish data, negotiate usage agreements, and access data.
Timeline of the Data Spaces Blueprint
The Data Spaces Blueprint is one of the outcomes of the Data Spaces Support Centre which has started in October 2022. The Data Spaces Blueprint will continuously evolve in the upcoming years and include the latest state-of-the-art and developments in the field of data spaces.
The first version of the Data Spaces Blueprint is released in September 2023 as Data Spaces Blueprint 0.5. Next, every 6 months a new version of the blueprint will be released in so called heartbeats. This continuously releasing of new versions enables the DSSC to quickly respond to new developments. Finally, the last version of the Data Spaces Blueprint is expected in January 2026.
The first version of the Data Spaces Blueprint (0.5) includes information and definitions on all building blocks, candidate standards and reference implementations. The next version (1.0) released in March 2024 also contains a list of standards and reference implementations for each building block. Moreover, the detailed integration between the building blocks is described in the Integration Document.
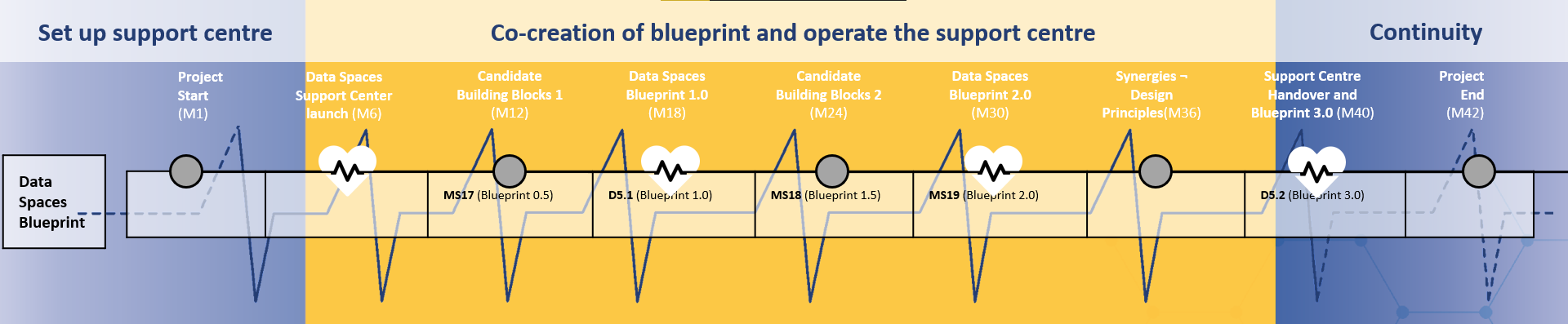
The planning of the Data Spaces Blueprint.
Feedback
Building the Data Spaces Blueprint is only possible in collaboration with you! Data Spaces is now arrived in an interesting and dynamic environment: numerous data spaces are being setup in various domains, (open-source) technologies are continuously being developed, and the new knowledge is being developed pushing the state-of-the-art. Therefore, we are collaborating with a broad network of stakeholders, community of practice, and experts in order to continuously update the Data Spaces Blueprint to include the latest developments.
We would love to also hear your feedback. Is something unclear? Did you find a mistake? Are we missing an important topic? Please let us know! You can contact us via our website.